1) Quais são as diretrizes informais para o projeto de esquema de relações? Explique resumidamente cada uma. Semântica de atributos.
• Redução de valores redundantes em tuplas.
• Redução de valores nulos em tuplas.
• Não permissão de tuplas espúrias.
Semântica de atributos.
Assume-se que certo significado esteja associado aos atributos, para todo agrupamento de
atributos que formam uma relação esquema. Intuitivamente, verifica-se que cada relação pode
ser interpretada como um conjunto de fatos ou declarações. Este significado, ou semântica,
especifica como podem ser interpretados os valores de atributos armazenados em uma tupla
da relação, em outras palavras, como os valores de atributos estão relacionados uns com os
outros. Em geral, é mais simples descrever a semântica de relações, ao invés da semântica de
atributos de uma relação.
Diretriz 1ª: Projetar um esquema de relação de maneira que seja simples descrever seu
significado. Normalmente, isso significa que não se pode combinar atributos de múltiplos tipos
de entidades e tipos de relacionamentos numa simples relação. Intuitivamente, se um esquema
de relação corresponde a um tipo de entidade ou tipo de relacionamento, o significado tende a
ser claro. Por outro lado, tende ser uma mistura de múltiplas entidades e relacionamentos e,
assim, semanticamente não-clara.
Redução de valores redundantes em tuplas
Deve-se minimizar o espaço de armazenamento utilizado pelas relações básicas:
_ Agrupe atributos em esquemas de relações;
_ Deve-se evitar situações que caiam em problemas de Anomalias na Atualização.
Modelar esquemas de relações básicas de forma que nenhuma anomalia de atualização possa ocorrer nas relações. Se houver a possibilidade de ocorrer alguma anomalia, registre-a claramente e tenha certeza de que os programas que atualizam o banco de dados operarão
corretamente.
_ Pode-se violar uma diretriz em prol do desempenho de uma consulta, entretanto, as medidas cabíveis devem ser tomadas para que os dados estejam sempre
consistentes e íntegros.
Redução de valores nulos em tuplas.
A existência de muitas possibilidades de uso do valor null causa desperdício de espaço no armazenamento e gera problema de entendimento do significado do atributos e da especificações de joins, e funções agregadas.
_ Motivos para uso do null:
_ O atributo não se aplica à tupla;
_ O valor do atributo para a tupla é desconhecido;
_ O valor do atributo para a tupla é conhecido, mas ausente, ou seja, ainda não foi registrado
Até onde for possível, evite colocar os atributos em uma relação básica cujos valores freqüentemente possam ser nulos. Se os nulls forem inevitáveis, tenha certeza de que eles se aplicam somente em casos excepcionais e não na maioria das tuplas da relação.
_ Ex: se só 10% dos empregados tiverem escritórios particulares, há pouca justificativa para incluir um atributo ESCRITORIO-NRO na relação EMPREGADO; pode ser criada uma relação EMP_ESCRITÖRIOS (ESSN, ESCRITORIO_NRO) que contenha apenas as tuplas dos empregados que possuírem escritórios particulares.
Não permissão de tuplas espúrias.
Considere os esquemas de relação EMP_LOCS e EMP_PROJ1 que pode
substituir a relação EMP_PROJ da Figura 9.1b.
Uma tupla em EMP_LOCS significa que o empregado cujo nome é ENOME trabalha em algum
projeto cuja localização é PLOCALIZAÇÂO. Uma tupla em EMP_PROJ1 significa que o
empregado cujo número do seguro social é NSS trabalha HORAS por semana em um projeto
cujo nome, número e localização são PNOME, PNUMERO e PLOCALIZAÇÂO. A Figura 9.4b
mostra a extensão de EMP_LOCS e EMP_PROJ1 correspondente à relação extensão
EMP_PROJ da Figura 9.3, aplicando-se operações de projeção (¶) adequadas.
Suponha agora que EMP_PROJ1 e EMP_LOCS sejam utilizadas como relações base ao invés
de EMP_PROJ. Isto seria, particularmente, um projeto ruim, pois não se pode recuperar as
informações que existiam originalmente em EMP_PROJ a partir de EMP_PROJ1 e
EMP_LOCS. Se uma operação JOIN-NATURAL for aplicada em EMP_PROJ1 e EMP_LOCS,
surgirão mais tuplas que existiam em EMP_PROJ. A Figura 9.5 ilustra o resultado obtido
aplicando-se o join, considerando apenas as tuplas existentes acima da linha pontilhada, para
reduzir o tamanho da relação resultante. As tuplas adicionais são chamadas tuplas espúrias
porque elas representam informações espúrias ou erradas, e por isso elas não válidas. As
tuplas espúrias estão marcadas por asteriscos (*) na Figura 9.5.
A decomposição de EMP_PROJ em EMP_PROJ1 e EMP_LOCS é ruim porque quando é
aplicada a operação JOIN-NATURAL, não são obtidas as informações originais corretas. Isto
porque foi escolhido PLOCALIZAÇÃO como o atributo que relaciona EMP_LOCS e
EMP_PROJ1, e PLOCALIZAÇÃO não é nem uma chave-primária
2)Quais são as métricas de qualidade informal para projeto de esquemas de relações? Explique resumidamente cada uma delas.R: São quatro métricas (Semântica de Atributos, Informação redundante ou anomalias de atribuição, valor null em tuplas e não permissão de tuplas espúrias).
3)O que é e para que serve o conceito de dependência funcional? Quais são os tipos de dependência? Explique-osR: dependência funcional: Dependências Funcionais são restrições ao conjunto de relações válidas. Elas permitem expressar determinados fatos em banco de dados relativos ao empreendimento que se deseja modelar. Anteriormente foi definido o conceito de superchave. Para existir o destino (dependência -->chave estrangeira) tem que existir a origem (chave primaria). O atributo deve realmente caracterizar a relação.
4)O que é e para que serve normalização de dados relacionais? Quando será utilizada a normalização na maioria das vezes?R: Eliminar redundâncias e inconsistências de um banco de dados, com reorganização mínima dos dados, é o processo pelo qual transformamos um BD fora do padrão do m-rel, num BD normalizado (dentro do padrão m-rel). Normalmente é usado em BD antigos ou criado por pessoa não técnica.
5)O que são e quantas são as formas formais de relação? Explique-as resumidamente. Para manter eficiência e a simplicidade de processamento em certos casos podemos normalizar as relações até a 3ºFN por quê?R: O objetivo da normalização de um banco de dados é evitar os problemas que podem provocar falhas no projeto do banco de dados, bem como eliminar a mistura de assuntos e as correspondentes redundâncias dos dados desnecessárias. O processo de normalização aplica uma série de regras sobre as tabelas (também chamadas de relações) de um banco de dados, para verificar se estão corretamente projetadas.
Primeira Forma Normal: A primeira forma normal enuncia que cada atributo de uma entidade ou relacionamento pode armazenar apenas um valor. Tabelas com atributos multi-valorados não são consideradas em 1NF.
Segunda Forma Normal: A segunda forma normal (2NF) descreve que todo atributo deve ser determinado unicamente pela chave primária. Se existem atributos que dependem apenas de parte da chave, estes devem ser separados em tabelas onde a 2NF seja obedecida.
Terceira Forma Normal: A terceira forma normal (3NF) exige que a tabela esteja em 2NF e que todos os atributos que não são chave sejam mutuamente independentes, isto é, que não existam funções que definam um ao outro. Portanto, sempre a chave por inteiro deve definir toda a tabela.
Forma normal Boyce/Codd (BCNF): Definição que engloba as outras formas normais, e define que uma tabela está em BCNF se, e somente se, todo determinante funcional for em relação a uma chave candidata. Na prática, uma tabela está em BCNF se estiver em 3NF e não existir dependência funcional dentro da chave primária.
6- Dê exemplos de normalizações de uma relação.Tabela normalizada
Atributos não atômicos ou contém tabelas aninhadas
Exemplo: Tabela de alocação de funcionários a projetos
Código do Projeto: 1
Tipo: Desenvolvimento
Descrição: Vagas
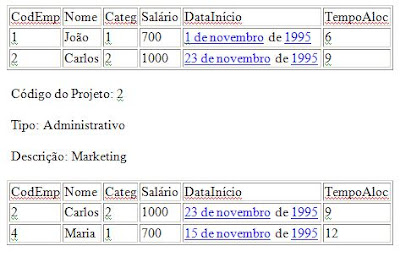
A seguinte tabela descreveria os dados acima apresentados: Projetos(codp, tipo, descrição, empregados(code, nome, categ, salário,data_início, tempo_aloc)).
Tabela não normalizada empregados é um atributo não atômico.
[editar] Primeira Forma Normal
Definição (note que relacionamentos como são definidos acima são necessariamente na 1NF)
"Uma tabela está na 1FN, se e somente se, não possuir atributos multivalor."
Definir relações NFNF
• como transformar relações NFNF (também chamadas relações UNF) em relações 1NF
o como transformar as restrições chave de relações aninhadas
o como transformar as dependências funcionais de relações aninhadas
Passagem à 1FN:
• Gerar uma única tabela com colunas simples
• Chave primária : id de cada tabela aninhada
Exemplo: Projetos(codp, tipo, descrição, code, nome, categ, salário, data_início, tempo_aloc)
Problemas:
• Redundância
• Anomalias de Atualização
[editar] Segunda Forma Normal
Definição:
Uma relação está na 2FN se, e somente se, estiver na 1FN e cada atributo não-chave for dependente
da chave primária inteira, isto é, cada atributo não-chave não poderá ser dependente de apenas
parte da chave.
No caso de tabelas com chave primária composta. Se um atributo depende apenas de uma parte da chave primária, então esse atributo deve ser colocado em outra tabela.
Passagem à 2FN:
• Geração de novas tabelas com DFs completas
• Análise de DFs:
* tipo e descrição - DF de codp
* nome, categ e salário - DF de code
* data_início e tempo_aloc - DF de toda a chave
Resultado:
• Projetos(codp, tipo, descrição)
• Empregados(code, nome, categ, salário)
• ProjEmp(codp, code, data_início, tempo_aloc)
Conclusões:
• Maior independência de dados (não há mais repetição de empregados por projeto, por exemplo)
• Redundâncias + Anomalias - DF indiretas
[editar] Terceira Forma Normal
• definição
“ Uma relação R está na 3NF, se ela estiver na 2NF e cada atributo não chave de R
não possui dependência transitiva, para cada chave candidata de R.”
Passagem à 3FN:
• Geração de novas tabelas com DF diretas
• Análise de DFs entre atributos não chave:
- salário - DF de categ
Resultado:
• Projetos(codp, tipo, descrição)
• Empregados(code, nome, categ)
• Categorias(categ, salário)
• ProjEmp(codp, code, data_início, tempo_aloc)
Conclusões:
• Maior independência de dados
• 3FN gera representações lógicas finais na maioria das vezes
• Redundâncias + Anomalias - DF multivaloradas





























































